Extracting structured data from PDF plans
In this post, we want to focus on plans, which are usually received in PDF format. What are common use cases where structured information from such PDF plans might come in handy? And what methods do we use in order to extract the information?


The Challenge and Use Cases
At elevait, we deal with the extraction of structured information from unstructured sources. One example for such unstructured data sources can be found in the construction industry, where information is typically shared and exchanged in the form of plans and text documents. In this post, we want to focus on plans, which are usually received in PDF format. What are common use cases where structured information from such PDF plans might come in handy? And what methods do we use in order to extract the information?
A typical construction project can involve hundreds of documents including dozens of plans. So, a first task might be to find the relevant documents for the specific question at hand.
Possible use cases:
- sorting of files by project, topic etc.
- finding plans among many other documents
- extracting or searching for specific plan metadata (“Who wants to build what, when and where?”)
- georeferencing a plan, i.e. putting it on some external map
- using existing plans to create new ones, e.g. combining several partial plans from one larger construction site
- locating specific objects in a plan
Presenting elevait in:plans
With our product elevait in:plans, we tackle all of the above-mentioned use cases and offer individual services that can be wired together according to customer needs. A typical customer pipeline consists of several distinct processing steps that ask for different methodologies.

Example data pipeline:
- unpacking of project archives into individual files
- splitting of files into pages
- classification of pages by plan vs. no-plan (and routing to specialized subsequent extraction)
- extraction of plan metadata according to customer-defined semantic classes and export of the metadata according to customer demands
- finding the map area and coordinate axes in a plan in order to perform the georeferencing, i.e. transformation to world coordinates
- extraction of all geometries from a plan
- merging of geometries from different plans in a project
- transformation to a customer-defined target coordinate reference system
- export of the (georeferenced) geometries into different formats (GeoJSON, typical GIS or BIM formats)
The classification tasks, for example, we typically solve using common machine learning approaches with vision-based or multi-modal (image plus text) neural networks. But how do we tackle tasks such as the metadata extraction or the georeferencing of the objects in a plan? How can we even get the text content or the geometries contained in a PDF file? This can be a difficult task because PDF files are built around visual appearance, not structured information.

To this end, we make use of an excellent external library, PyMuPDF, which enables us to extract both the geometries as well as the text contained in a PDF file by using straightforward commands.
PyMuPDF for the extraction of the underlying raw PDF data
PyMuPDF is a cross-platform Python library provided by Artifex Software, which is based on bindings to the MuPDF C library. It provides several high-level functions for accessing objects in a PDF file. Writing such functions oneself is non-trivial because of the way how objects are laid out inside the PDF file format.
Both text and vector graphics are saved in (possibly compressed) content streams. And text does not have to be present in the form of consecutive characters forming words and lines, but can be given as individual glyphs arbitrarily placed on the page. It can even be given as a series of drawing instructions only, rendering it practically impossible to extract whole words without relying on Optical Character Recognition (OCR) or similar methods. Vector graphics are defined in the form of these same drawing directives, which are based on the PostScript language.
PyMuPDF, now, provides several very useful functions for the extraction of text and also the geometries in a PDF document. We focus here on two such functions. The first, Page.get_drawings(), gives us all geometries as ready-to-use Python objects such as lines, rectangles, and so forth—all with their corresponding style information like edge color, fill color, dash pattern etc. So no need for us to parse the drawing directives ourselves. The second function, Page.get_textpage(), gives us the texts in a document and already performs the merging of individual characters to words and blocks. PyMuPDF even allows one to transparently use Tesseract as OCR engine in order to read characters that are only given as series of drawing instructions. So no need for us to fiddle with these things on our own.
These two functions form the backbone for all our subsequent extraction and interpretation steps. The texts are essential for several of our pipeline steps. We need them in order to extract the metadata from the page, but also to, e.g., get the tick labels around the map area, which we use to find the transformation to world coordinates for the georeferencing. The geometries, on the other hand, are also needed for the georeferencing, which can make use of coordinate marker crosses within the map area in order to define the coordinate grid. And, of course, we want to extract the geometries for all subsequent parts of our pipeline such as plan merging, object detection, and the final export into the formats our customers choose.
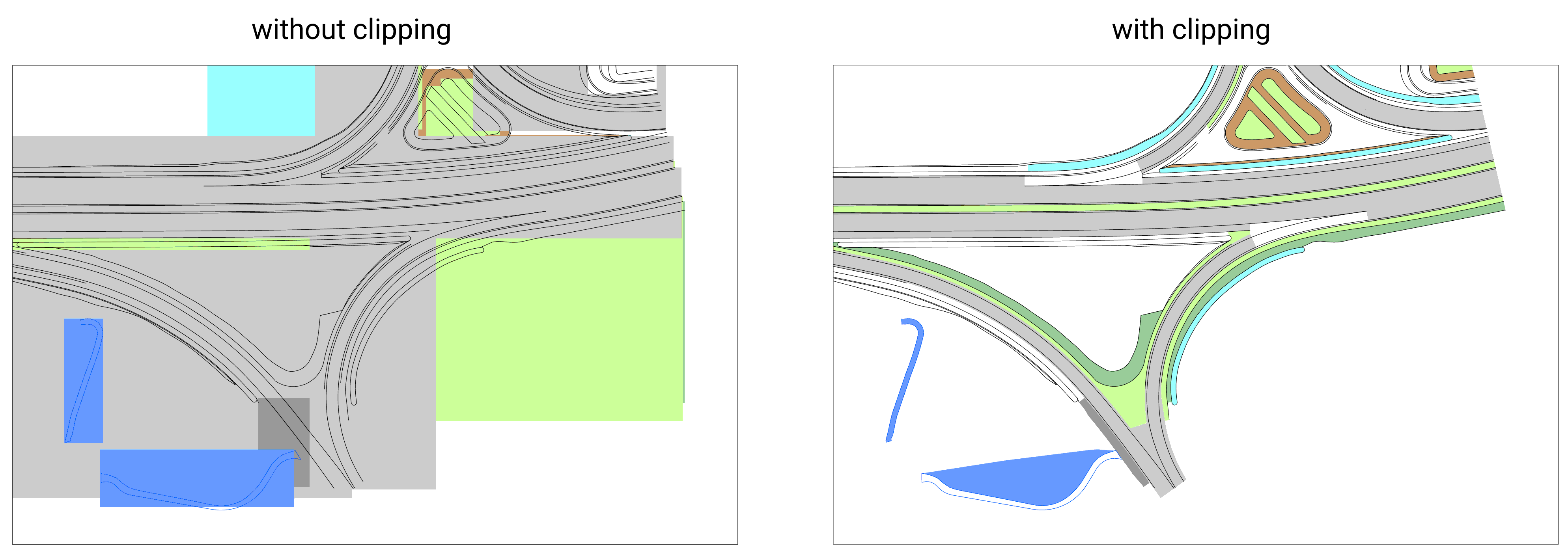
Challenge: Path clipping
But not always are the (styled) geometries in a PDF document given in an explicit form. Some plans make heavy use of clipping, which is a well-known feature of the PDF (and Postscript) format.
How does it work? Rather than defining the styled geometries directly, one can also define a larger solid area,e.g. a rectangle, given a certain style such as a fill color and then define clip paths that actually cut out the desired geometry from the solid area. This is useful, e.g., when several objects need to have the same style.

Unfortunately, when dealing with styles and filled paths for the first time, we recognized that PyMuPDF did not support clipping. This is when we decided to reach out with a feature request in the PyMuPDF issue tracker for the implementation of some limited support for clip paths. We were not asking for PyMuPDF to actually perform the clipping (i.e. calculating the intersections of paths)1, but for the easier solution to also (optionally) return the clip path information from the PDF file in the API of Page.get_drawings(). Given this information, we are then able to perform the clipping on our side. Our feature request was very well received and the main developer of the PyMuPDF package came up with a working prototype for our feature request very quickly. This enabled us to now fully support clipping in our product elevait in:plans as well. And since PyMuPDF is open-source software, everyone can benefit from this change in the library.
Our interactions with Artifex
Since back then we have stayed in close contact with the developers of PyMuPDF. Meanwhile, we wrote plenty of smaller issues, all of which have been dealt with very fast. This customer support and the feature-rich API make PyMuPDF stand out among its few competitors in the open-source landscape.
Recently, Artifex published a case study about our use of their library as well.
Conclusion
In this blog post, we have shown what typical use cases of our product elevait in:plans look like. With this product, we are automatically processing plan documents from the construction industry. We explained that in order to extract structured information from unstructured PDF source files we make use of the PyMuPDF library. This library enables us to extract text and geometry content from such PDF files through a high-level API. Furthermore, we remain in regular contact with its maintainers who implemented a new feature, the extraction of clipping information, specifically for us. Due to this new feature, we are now able to also support input documents that make use of clipping. From such documents we can extract the plan metadata as well as all geometries contained in their map areas. We are georeferencing those geometries and are able to merge geometries from different plans belonging to one common project. We can export the geometries in a customer-defined coordinate system and into a format of their choice for further processing. Using our automatic pipeline, we can reduce the number of necessary manual steps for our customers and thereby increase their overall efficiency.
1 Clipping involves rather complicated geometric calculations in the general case. There exist good libraries that actually perform these calculations, but one of PyMuPDF’s design goals is to not depend on other software packages. That is why having this task actually performed by PyMuPDF was out of the question.



.svg)
