Out of Domain Detection: AI cannot know Everything - And does not need to
AI models being able to handle unexpected inputs and maintain accuracy in their predictions can make a difference. Staying ahead has never been more important. With AI becoming increasingly prevalent, understanding Out-of-domain-detection is crucial.


The world can be a scary place. As we go about our daily lives, we sometimes find ourselves in situations we neither expected nor prepared for. Like running into an old school friend on the way to work: "Oh, Hi Mark, haven't seen you for years. How is life?". As human beings we are equipped to deal with these situations, some perhaps better than others, and our minds can quickly adapt and produce an appropriate answer.
The closed vs the open World Assumption

AI models can face the same challenges. Let's take a very simple example of a model being trained to distinguish between images of cats and dogs. Typically, AI models are trained under what is known as the closed world assumption. For our example, this means that the model only sees pictures of cats or dogs during training. All our model can do is decide between them. The most uncertainty it can express would be for something that only exists in cartoons, like CatDog, that is just right between the two classes (50% cat, 50% dog). But as we all know, the world is not just cats and dogs. Using the model from our example in a real world environment, we might also encounter pictures of other cute animals, such as fluffy little bunnies.
How does the model react when it's confronted with this unknown input?

Well, the model will output with a high probability that the bunny must belong to one of these classes. This is what is called a silent failure.The real world is not limited to the classes that the model knows from training. There are a million things the model has never seen before.
Out-of-domain detection is about making the model aware of the unknown and therefore using the open world assumption. Just like humans, it is ok for a model not to know the answer to all questions. They just need to be aware of it. To put this in more philosophical terms: We do not want to leave our models unprepared, bound to only knowing the shadows of the real world like the imprisoned in Plato’s allegory of the cave. We believe that models should be able to represent realistic conditions.
Real-world examples
Let’s face it: The cats and dogs model is not a profitable business case. Let's move on to some more real-world examples.
Unsupported inputs: Chatbot
Today, more and more companies are using chatbots to mimic human-like conversations with their customers. These are often powered by AI, and can help automate simple requests or provide general information to users in a more interactive way.Imagine there is a chatbot that can teach people about AI. It is well designed and can answer many questions about the technology and integration of such systems. The user can freely type any input, they could ask any question, such as: "Is mayonnaise an instrument?"

Obviously, our model would not be prepared for this and would most likely give an answer specific to the domain for which it has been trained.The user now feels misunderstood, they may try to rephrase the question but never get the expected answer. This is clearly not a good user experience, and it would be much better if the chatbot knew when it could not answer a question, rather than giving a seemingly random output.
Domain shift: Providing best practice from the energy sector
Our modern world is constantly evolving. Fashion, technology, language, politics - everything around us is in constant flux. Real-world AI applications will have to deal with this so-called domain shift throughout their lifetime.
An example of this is the recent energy crisis. While we were working on automated recognition of customer enquiries for the energy provider SachsenEnergie AG, we noticed that the customer support department was suddenly flooded with emails from people worried about the consequences of recent events.
These emails did not match any of the previously known customer requests. They could easily be mistaken for spam. In difficult times like these, you don't want to accidentally ignore your already anxious customers.
This also shows that domain shifts can happen suddenly. There is no guaranteed period of time before the input data can change and constant monitoring is a necessity.
You can’t predict 100 % of the risks.
Domain shifts or unsupported inputs are just two of the many things that can happen to an AI model out there in the real world. While you may not be able to think of something as a potential risk right now, no system is 100% safe unless it is deployed in a completely controlled environment. Models should therefore be able to handle real-world conditions if they are to process real-world data.
Methods for out-of-domain detection
We have highlighted many potential risks, but AI models are not helpless. So let us move forward and look at how we can prepare for the open world. There are two basic types of methods for dealing with out-of-domain data:
Supervised Methods
For these, it is necessary to collect data that should be classified as out-of-domain. This is not an easy task as there is generally no clear definition for such data. It is just any sample that deviates significantly from the norm. With this vague definition, there are potentially infinite numbers of samples that would need to be collected. The result is that you can collect some out-of-domain samples, but you can never collect all the potential types that could be input into the model. Going back to our example of cats and dogs. It might be possible to collect images of a few other animals, such as bunnies and birds, but it would be difficult to find some samples for every possible species. There may always be an animal that was not part of the collected data and could be misclassified.
Unsupervised Methods
These methods simply calculate a score for each sample they face. The higher the score, the more the sample deviates from the data the model was exposed to during training. This means that samples with a high score are likely to be out-of-domain. These methods do not require out-of-domain data and are therefore more suitable for a real-world scenario.
What do our AI models bring to the table that could help us get these scores?
So let's change the cat-dog example. Imagine you have a large collection of different fruits, such as apples, oranges and bananas. Each fruit has certain characteristics such as color, shape and taste. Let's say you want to organize these fruits in a way that captures their similarities and differences.
Embeddings are a way of doing just that. It essentially means representing each fruit as a set of numbers that capture its important features. These numbers can be thought of as coordinates in a multi-dimensional space. For example, you might have a 2-dimensional space where the x-axis represents sweetness and the y-axis represents acidity. Using an embedding technique, you can map each fruit to a specific point in this space based on its sweetness and acidity values. So apples, oranges and bananas would each have their own unique coordinates in this space.
The beauty of embeddings is that they can capture complex relationships between objects. For example, if two fruits are similar in terms of sweetness and acidity, their corresponding points in the embedding space will be closer together. Conversely, if two fruits are very different in terms of taste, their points will be further apart. Internally, each AI model generates these embeddings to represent all kinds of data, such as images, text or even video. Usually these have many more than 2 dimensions, e.g. Google’s model BERT has more than 500. But these obviously would be impossible for humans to comprehend, so let us stick to our simple fruit example for now.

How can we use these embeddings?
Distance-based methods aim to measure the dissimilarity or distance between these embeddings. In out-of-domain detection, the idea is to compute distances between the known in-domain data and new incoming samples. This distance can then be used as a score to classify samples as in- or out-of-domain. At school, everyone should have at least heard of the Euclidean distance, which is basically just the straight line between two points. But in the world of statistics, there are more and much cooler (in a nerdy way) distances. One of them, which is suitable for our use case here, is the Mahalanobis distance.
The Mahalanobis distance is a measure of the distance between a point and a distribution, not just between two data points, so it takes into account the relationship between the underlying features. If we look at a distribution of fruits, we can see a relationship between the features. Fruits with a higher level of acidity don't seem to be very sweet, so there is a dependency between the features for this distribution.
Mahalanobis distance takes this spread and orientation of the data into account and can provide a more accurate measure of dissimilarity than Euclidean distance. Finally, let's illustrate this using a small out-of-domain detection task. We now have two new samples in our distribution: tomato and cherry. The task is to decide whether they are fruits (in-domain) or not (out-of-domain). If we compute the Euclidean distance from the mean of the distribution (the average fruit, so to speak), we might end up with the same distance even though one data point is far away and the other is clearly part of the distribution. The Mahalanobis distance would take into account the skewness of the distribution and end up with very different distances for the two samples, emphasizing that the cherry is a fruit and the tomato is not (at least from a culinary point of view).
Outputs of the classifier
The embeddings alone are only a representation of the data. They could still be used for different classification tasks. For example, instead of deciding between fruits and vegetables, we could try to predict the color of a fruit (this shows that not every embedding space has the same value for all tasks). To actually solve a concrete task, we would need a classifier that uses these embeddings to make a qualified guess.
When the classifier analyzes an input, it provides a confidence score or probability for each category it has been trained on. These probabilities represent how certain the classifier is that the input belongs to each class. These confidence scores are not inherently very good for out-of-domain detection, but there are several ways to turn them into meaningful scores. Using the outputs of the classification does not add too much complexity to the model and can already give decent detection results.
Hopefully this has shown you that models are well equipped to deal with these situations. The methods we have highlighted are just the really basic ones. There are much more complex approaches that try to make models as robust as possible. If you are interested in the more technical side, here are some more papers on out-of-domain detection that show some really cool ideas.
- Out-of-Domain Detection for Low-Resource Text Classification Tasks
- VOS: Learning What You Don't Know by Virtual Outlier Synthesis
- ViM: Out-Of-Distribution with Virtual-logit Matching
Out-of-domain samples in the wild
Now that we have seen some ways of calculating these scores, how can we best use them in practice to make our model more robust?
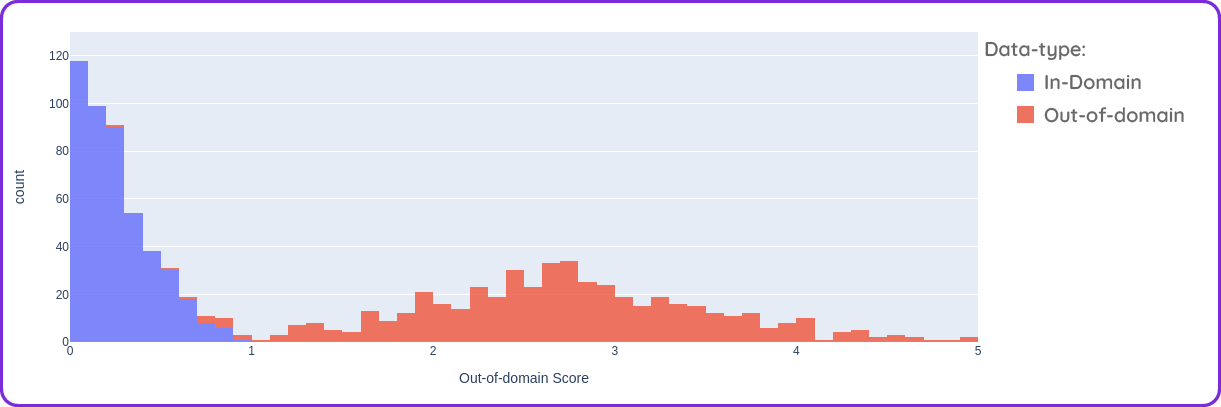
In the end, we have to decide on a certain score that will act as a cut-off between in and out of domain. This is called a threshold, and it's not trivial to set one. The scores can be highly dependent on the use case. It is best to have a test set with realistic data to look at the results. If we have a good out-of-domain detection method, we might end up with scores like in the graph above. The scores for the in-domain data should be close to 0, while the out-of-domain scores should be somewhat spread out and mostly higher.
As you can see, the bars overlap for some of the scores, which means that a perfect separation between in and out of domain is not possible. For most real world scenarios this will be the case. How to set a threshold depends on the use case of the model. It is mainly a question of risk versus coverage. How many samples can we automate and what is the risk of misclassification? Because of the constantly evolving data that the model will encounter in use, the score distribution would always be subject to change, so the threshold should be re-evaluated constantly.
The final question is, what do we do when we encounter potentially out-of-domain samples in our live system?
For some use cases, such as a chatbot, we don't really have a choice, but can only choose to reject automatically. This would usually take the form of a response like "Sorry, I did not understand your question". Since a misclassification here would only mean that the user should perhaps try to rephrase their question, this fully automated strategy is fine.
Taking our other example from the beginning, customer support for energy providers, this would be a completely different situation. Having an important email from a customer mistakenly classified as out of domain and never read by a human could be disastrous for the company's image. In such cases, samples with a high score should be flagged for a human to look at. In this way, humans and AI systems can work together as a team to handle even the most challenging requests.

Conclusion
After all, a lot can happen in the open, wide world out there, and it is almost guaranteed that a model will encounter unexpected inputs in real-world applications. But there is no need to fear. There are many ways to prepare, and surely there is one for every potential use case. There is no challenge that a well-designed AI system with a bit of human supervision cannot overcome. We need to start thinking about humans and AI as a team, not as competitors for the same job.



.svg)
